Introduction
(I’d like to thank Jordyn Bonds, Nick Tittley and Brian Bossé for contributing to the discussion leading to this article)
The common belief is that reorganizing infrastructure teams will inherently improve efficiency and reduce costs. However, our key insight is that altering organizational boundaries does not fundamentally change the work required for cloud systems. It does impact the distribution of roles and responsibilities, and how teams interact and prioritize, but not the tasks involved in building and running cloud systems.
Reorganization shifts where the work takes place, not what that work fundamentally demands. Smaller companies may consolidate teams seeking economies of scale. Larger organizations decentralize to limit accumulated complexity. But the work remains the same.
Over the past two years we conducted hundreds of interviews with engineering leaders, CTOs, CEOs, heads of infrastructure and platform, DevOps organizations, teams and infrastructure engineers, and we’ve found recurring organizational models and tradeoffs across organizations. We’ll describe those models, the tradeoffs involved and what we think can be a new version of a model that leverages cloud intelligence to maintain more benefits with less tradeoffs.
Why Re-Org
Smaller companies often look to consolidate teams to find engineering efficiency gains. The goal of consolidation is usually to bring together duplicate infrastructure/cloud related efforts from multiple product orgs working in silos into centralized teams that work across the organization.
For example, instead of each team building and maintaining their deployment tooling, automation and systems operations, a central team can solve those problems once and then reuse those solutions for multiple orgs. Efficiency gains aren’t only in the engineering capacity needed to build and operate those systems, but also in optimizing the re-use of the infra resources like shared clusters for multiple organizations. Because the central infrastructure team has visibility into all product orgs, they have the ability to optimize within and across resources. This potentially saves dollars and engineering operational cost and is referred to as economies of scale.
Another, more psychological reason to re-organize infrastructure initiatives is to reduce application developers’ cognitive load. This is done by shifting non-application responsibilities to infrastructure teams and orgs. Product orgs can then treat the infra-org as a black box service provider to ask solutions of. The degree of cognitive load reduction depends on the organizational model and division of roles and responsibilities.
Larger companies have different reasons to re-org. Organizationally, product org leaders prefer to externalize non-core product responsibilities by giving them to central orgs like the infra org. This gives them one less thing to deal with outside of their domain of expertise. They can now set expectations (and blame) on the infrastructure org instead of dealing with it within their organization.
Companies with infra-platform orgs eventually consider decomposing them. The goal is to reduce the complexity of maintaining the custom and convoluted internal abstractions built up over time. They do this by re-tasking product orgs with more platform responsibilities, which causes those orgs to outsource solutions to native cloud providers.
Driven by these consolidation and decomposition forces, infrastructure orgs tend to evolve into a few canonical forms. From our research engaging with dozens of companies, these 4 models represent the primary organizational structures adopted.
4 Common Infrastructure Re-Org Models
Based on the many interviews we’ve had over the past 2 years, these are the 4 common organizational models that we’ve found. In many companies these were evolved from one to the other in this order, as explained in the evolution of infrastructure cloud blog post.
Product Orgs with Embedded Infra Teams
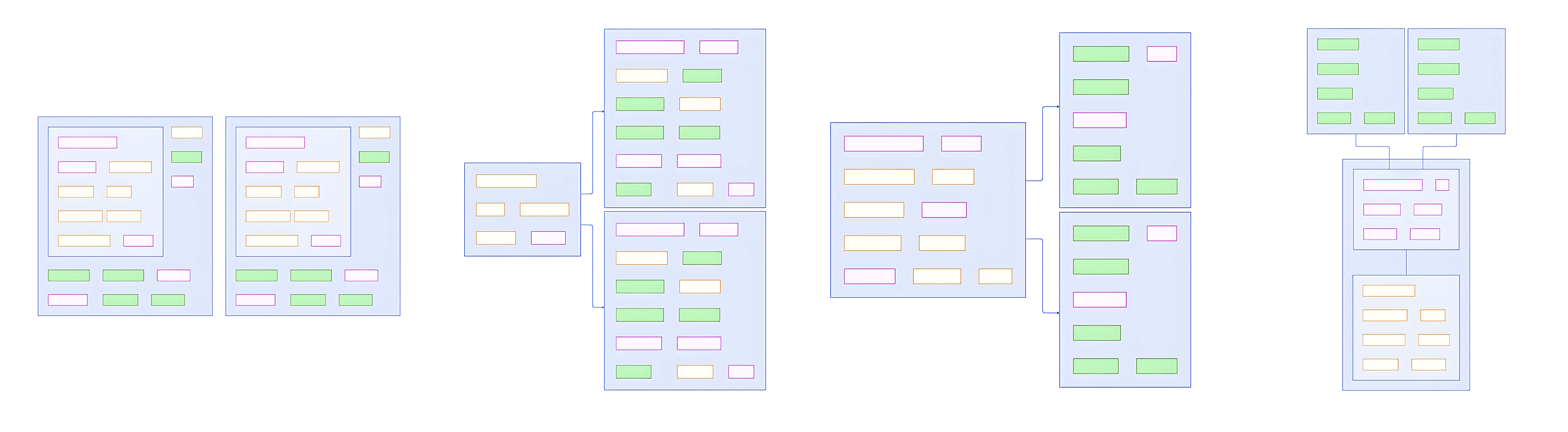
Most teams and companies start by having each team tackle their own problems separately - so each product org takes the entire set of cloud and infra responsibilities which works great for moving fast at the cost of full duplication of work:
This highly decentralized approach embeds infrastructure engineers directly within autonomous product teams. It maximizes flexibility and agility for product orgs to make infrastructure decisions tailored to their specific needs. Technology choices, provisioning, operations , and standards are all owned by each product team. There is complete duplication of work as they build out their own independent infrastructure. While this avoids bureaucracy, the duplication incurs substantially higher costs than leveraging centralized infrastructure. It also requires heavy coordination between product orgs for interoperability. This model suits early startups but may transition to more centralized platforms as duplication and complexity mounts over time.
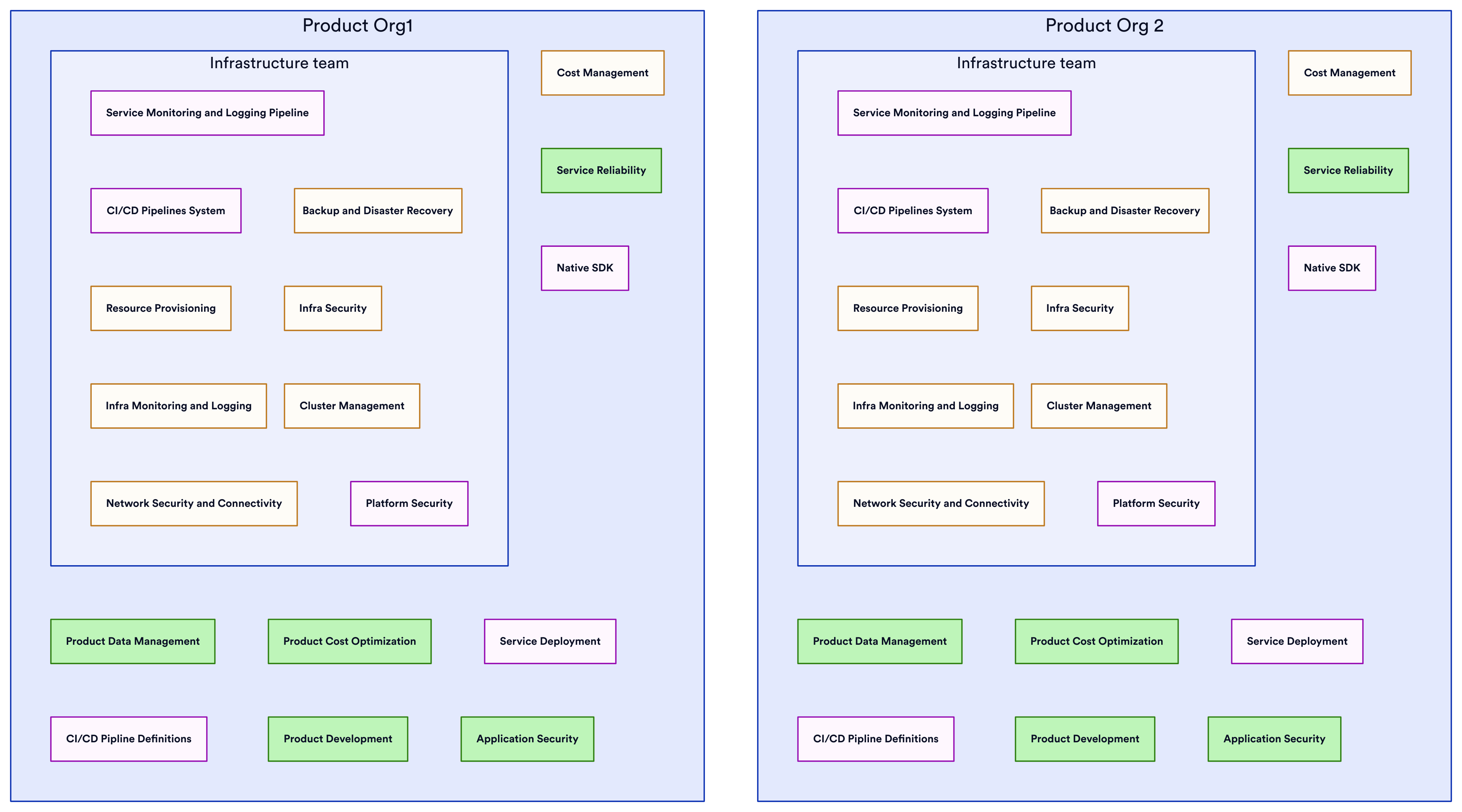
Shared Cloud Engineering Team and Product Orgs
The shared engineering team structure consolidates infrastructure engineers from disparate product teams into a central group:
This centralized cluster targets economies of scale and reduced duplication for aspects like cluster management, network configurations, and IaC templates. The shared team provides infrastructure building blocks and support to the product teams. But the product orgs maintain control over their own application operations and some provisioning needs. Rather than dictate standards, the shared team offers guardrails and guidance. This balances infrastructure consistency with product autonomy. There is less duplication than fully decentralized models but more than a consolidated platform org.
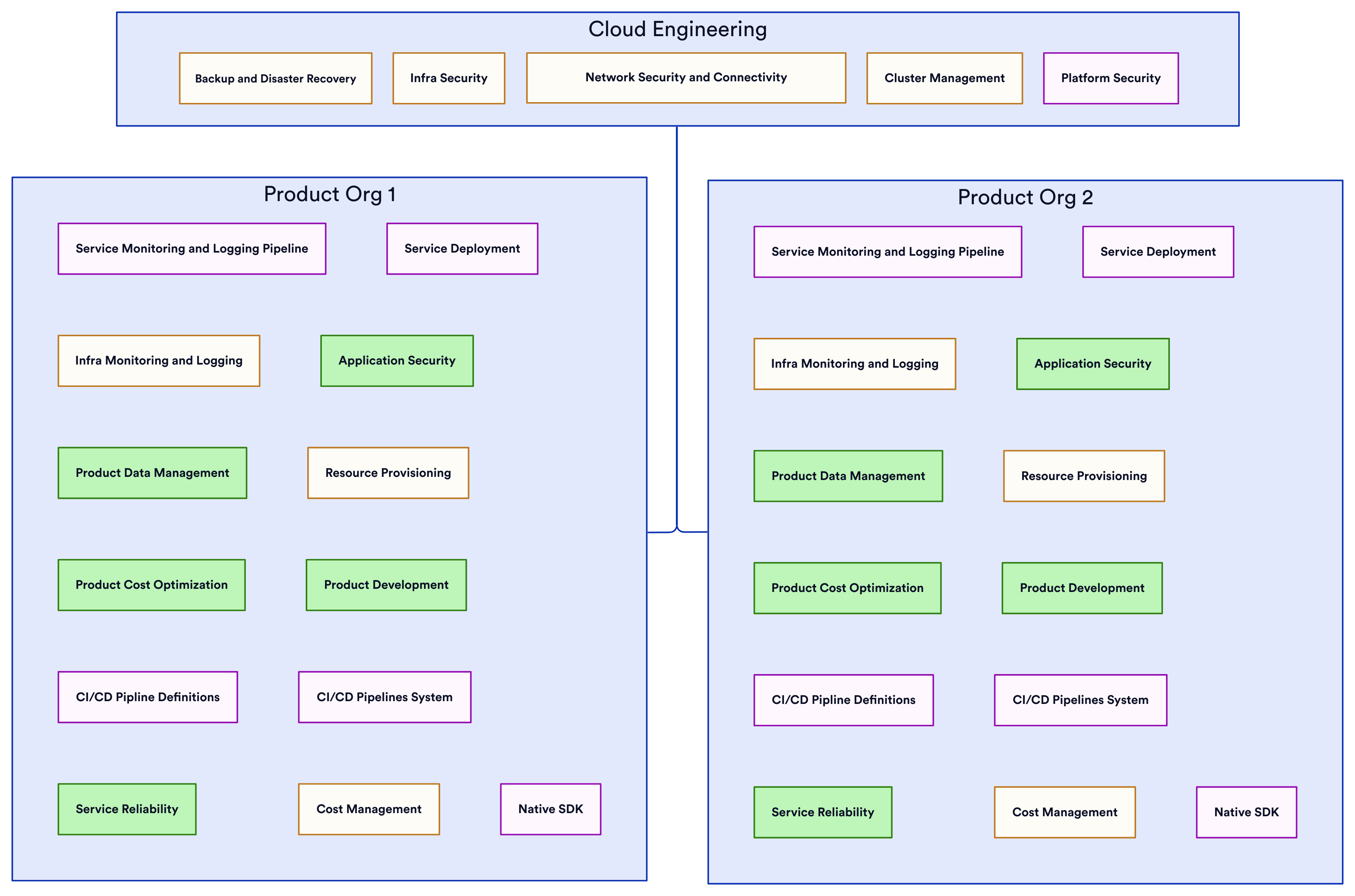
Infrastructure Org and Product Orgs
In this model, an infrastructure organization caters to common infrastructure needs across product groups and provides core services and some degree of standardization:
But product teams retain autonomy over their own application operations and provisioning requirements. There is flexibility in technology choices, with the infrastructure org aiming to curate options without completely restricting product teams. Alignment between infrastructure and product groups is essential for smooth workflows. Duplication of work can occur across product orgs, but is reduced compared to fully decentralized approaches. This structure attempts to balance standardization with product team ownership.
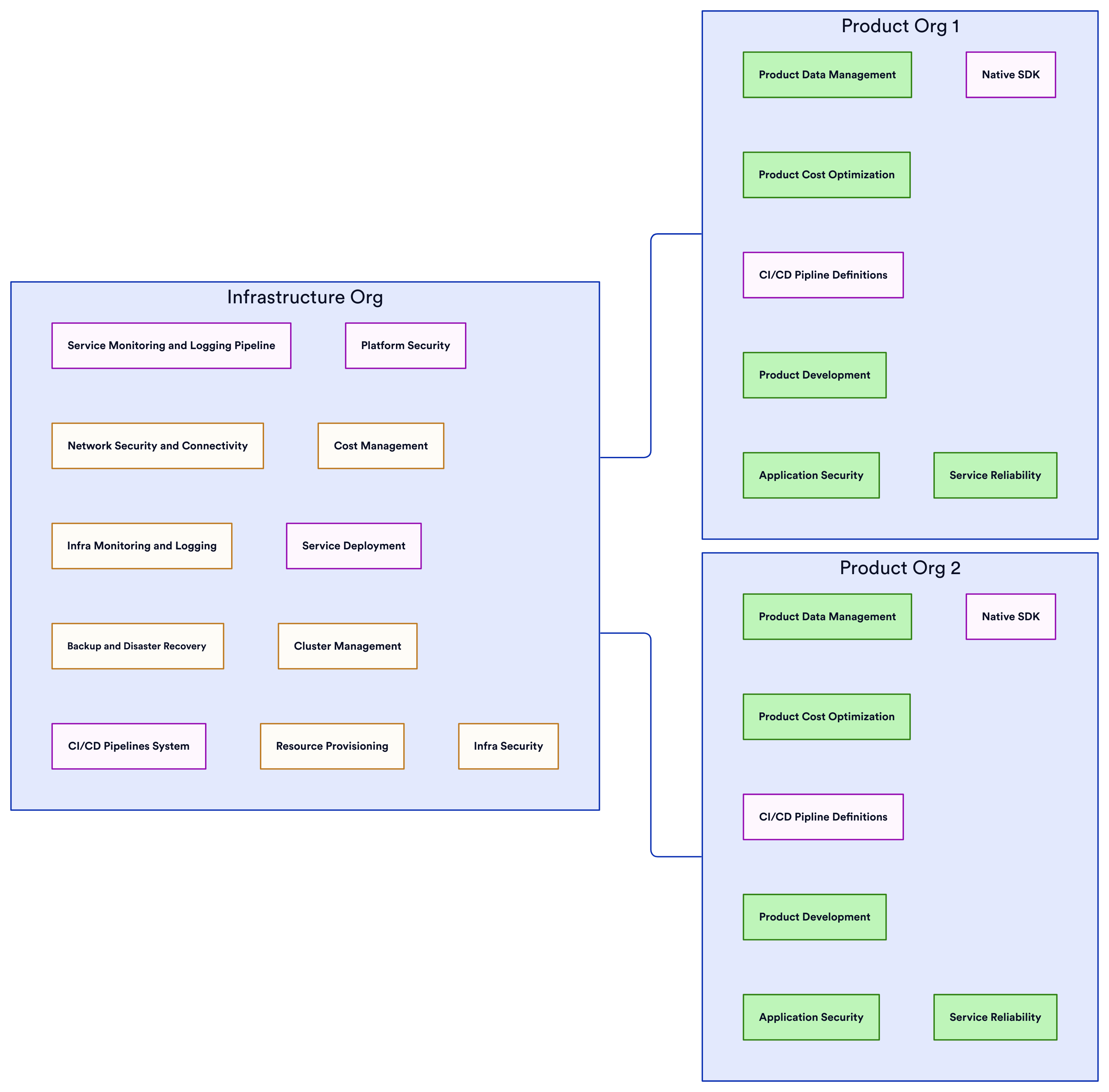
Infrastructure-Platform Org and Product Orgs
The Infrastructure-Platform Org model represents a highly centralized approach with a dedicated platform team owning all core infrastructure and standards:
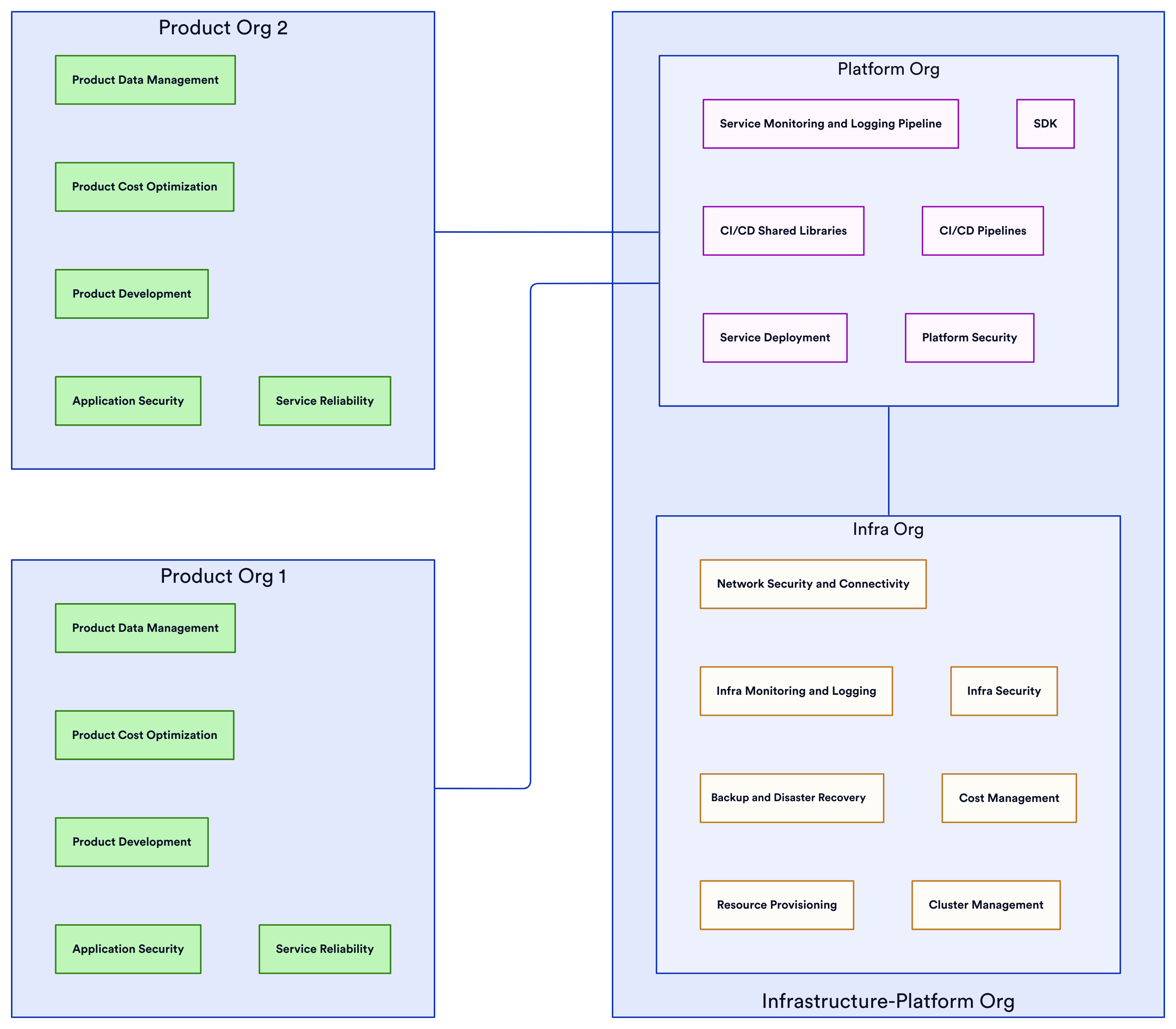
This singular group defines approved technologies, handles infrastructure provisioning, manages underlying services, and creates custom SDKs and abstractions for product teams. The goals are consistency across the organization and reducing duplication of work and cognitive load on product groups. However, the tight centralization risks the platform org drifting from actual product needs over time. And the accumulation of complex custom systems with convoluted internal abstractions can hinder agility.
Why Re-Orgs Fail
Based on our research, centralizing infrastructure team efforts and decomposing infrastructure efforts have 2 different sets of failure reasons.
Centralizing into Infrastructure-Platform Orgs
Multiple engineering leaders mentioned how dogma is aspirational, but not practical and they must be balanced appropriately. They highlighted how infrastructure experts’ dogmatic viewpoints created frustrating barriers for application teams.
In one example, a services team trying to debug a Java memory leak ran into issues, and previously they would SSH into VMs and attach standard tools to debug the application. This approach however no longer worked given containers’ short lifespan. This prevented developers from grabbing heap dumps to analyze memory usage trends. When the team requested SSH access to attach standard debugging tools to running containers, the experts refused because it was considered an anti-pattern. This refusal stemmed from the “cattle not pets” philosophy, which treats infrastructure as disposable commodities rather than units that can be singled out and getting special treatment. The experts’ rigid viewpoint prevented pragmatic solutions like temporarily accessing containers to collect diagnostics and forced the engineers to figure alternatives out, making the engineers miserable and unproductive.
If you can’t change your customer, you must adapt to them.
Other teams called out too many paper cuts in using the internal platform, but the infra-platform team did not understand why their meticulously detailed guides were not sufficient for adoption and believed it was engineers resisting change and not following the guides correctly.
At one company, there were growing frustrations between the application team and the infrastructure team. While the infrastructure team firmly believed their detailed onboarding tutorials were easy enough for developers to be productive, the application teams struggled. After months of back-and-forth, the infrastructure team agreed to observe the onboarding process directly via a Google Meet session. What followed was an unexpectedly painful 6-hour tutorial that highlighted the very real issues the application team faced, for example they found that some basic tasks like provisioning a single secret key took nearly 45 minutes to complete.
Rather than proving the developers were at fault, it became a sobering reflection of the infrastructure team’s limited application of empathy. This moment of empathy helped both teams set new expectations to address the underlying usability challenges. One could argue that the application engineers didn’t have the right skillset, but that’s where the centralization mindshift has to occur, and if they’re unable to solve the application engineers’ problems with the skillsets they mostly have, then they’ve made the wrong design decisions for the platform.
making the customer happy isn’t the same as solving the customer’s problem.
Infrastructure teams themselves reported feeling that centralized team leaders often did not push back on tech focused users demanding specific solutions.
At one company, the infrastructure team invested heavily in abstracting the aging service mesh implementation using Linkerd so it can replace it with the new hotness Istio. However, after many months of development adopting Istio enabled only minor reliability and simplicity improvements that didn’t meet business goals. The significant engineering effort to move to Istio was not justified, and was taken on because leads were not accustomed to pushing back and negotiating with their users. Had the infrastructure team been better equipped, they would have been able to get to the need behind the request instead of feeling limited to perform the exact remedy the customer demanded
Less mature infrastructure teams also faced issues with application engineers going directly to infrastructure people for help instead of using the official process. While not efficient, this allowed application teams to skip the formal way and get what they needed from infrastructure, especially when the official process was frustrating and slow.
For the application team, going directly to the infrastructure folks was often the easiest way to meet their goals when the official channels like prioritization meetings or extrapolating from documentation was too time consuming.
In some cases, these backchannel requests, which often were in private Slack messages, consumed over 30% of the infrastructure team’s time, making it hard to finish planned work. More application teams going directly to infrastructure reinforced this behavior since teams saw it could work.
While going directly can help get important things done despite bureaucracy, heavy use of unofficial requests can hurt trust in the process over time. It also duplicates effort to understand what teams need.
Heavy use of backchannels is a signal that your leadership structure is failing. Being draconian about it isn’t a solution, fixing leadership is.
Decomposing Infrastructure-Platform Orgs
Decomposition Reorgs often disrupt team dynamics, leading to the fragmentation of previously unified workflows. In effective central infrastructure-platform orgs, there are established mechanisms for cross-organizational prioritization, proactive planning, and a clear understanding of the purpose and scope of central teams compared to product teams. However when the org is decomposed, those systems are broken and will now need to be re-created where the responsibilities of the org were decomposed to, and all users who relied on it have to re-learn how to now interact with multiple orgs, both within their product group and outside of it.
When larger organizations break up their infrastructure teams to reduce the perceived accumulated complexity, engineering leadership often overlooks the fact that the total cost of ownership may not significantly decrease. The inherent complexity doesn’t disappear; it merely shifts onto the product organizations.As product features become more interconnected, the costs of engineering alignment and communication increase quadratically to the number of teams (N^2) compared to the linear costs facilitated by a central infrastructure team driving consistent standards and abstractions across different product organizations.
When infrastructure-platforms are decomposed, key personnel are likely to depart as the systems and abstractions they’ve built are being put to slow pasture, resulting in knowledge gaps. Subtle constraints and design rationales may be forgotten, leading new owners to re-implement currently effective systems and repeating past mistakes due to limited historical awareness of how those choices played out. This problem is further exacerbated when leadership changes, as the lessons learned from organizational evolutions have not been documented or institutionalized, and organizational repetitions have a much larger blast radius that’s hard to unwind.
One of the most commonly underestimated pitfalls is the cost of transitioning. Each time a company transfers responsibilities from one organization to another, there is a significant and costly transitional period that extends the total cost of ownership for many months or even years. These costs can be financial, such as needing to hire for the expertise being moved into an org or implementing new systems that were being offered centrally, as well as non-financial, such as decreased productivity during the transition period as engineers figure out what the new way of doing things should look like and how to account for the increased scope.
Organizational decisions are often influenced by a leader’s background. We have observed a pattern where newly hired engineering leaders, who previously worked in companies with infrastructure/platform organizations, tend to replicate similar structures without thoroughly analyzing their alignment with current internal constraints of the companies they’ve joined. Structures that worked in the past may no longer be suitable due to changes in technology, business objectives, or engineering capabilities. Attempting to implement an infra-platform org like ones that exist in companies like Meta, Google or Amazon will not fit companies like Etsy, Qualtrics and Docusign. Failing to grasp this contextual understanding leads to the repetition of previously attempted cycles, risking the recurrence of past mistakes at significant multi-year costs.
Tradeoffs and When to use What
Product Orgs with Embedded Infra Teams
This model is especially suitable for early startups or smaller organizations where speed and flexibility are paramount. With infrastructure engineers embedded directly within product teams, organizations can benefit from quick decision-making and tailored infrastructure solutions to meet specific product needs. This high degree of autonomy allows for dynamic customization and agility. However, the tradeoff for this flexibility is a higher duplication of work and cost, as each team builds and maintains their own independent infrastructure. Coordination between product orgs for interoperability can also be a challenge.
Pros:
- Infrastructure solutions fit the specific needs of each product org rather than being generalized
- Engineers can leverage their existing skills and familiar tools rather than having to learn new mandated tools
- Avoids abstraction layers on top of tools that can add complexity on top
- Flexibility to choose whatever tools work best for their needs instead of waiting for central approval
Cons:
- Duplicated engineering effort as each org builds and maintains infrastructure independently
- Interoperability is costly due to different technology choices and practices across orgs without central coordination
- Infrastructure resources tend to be under utilized, increasing total company costs
- Engineers take time ramping up when switching teams due to different tools/processes
- Autonomy allows teams to churn infrastructure tech even if not highly beneficial
- Collaboration across teams requires aligning both technical stacks and engineering cultures
Shared Cloud Engineering Team and Product Orgs
The Shared Cloud Engineering Team model is beneficial for organizations looking to balance infrastructure consistency with product autonomy. By consolidating infrastructure engineers into a central team, organizations can achieve economies of scale, reduce duplication of work, and provide shared resources and guidance to product teams. However, product teams retain control over their application operations and some provisioning needs, allowing for some level of flexibility. The tradeoff is that there is less duplication than fully decentralized models, but more than a consolidated platform org.
Pros:
- Reduces duplicated engineering effort by doing the work once for most orgs
- Lowers risks from team member turnover by retaining institutional knowledge within the central team
- Easier to disseminate best practices across multiple orgs
Cons:
- Prioritization tends to over index on urgent fire-fighting needs rather than important ones
- Lacks organizational structure to support having strong points of view on infrastructure
- Operates as an order taker rather than guiding infrastructure strategy
- Hard to enforce guardrails and consistency of cloud resources
- Product orgs still have the majority of operational responsibilities of clusters and infrastructure tooling
Infrastructure Org and Product Orgs
The Infrastructure Org model is fitting for organizations seeking to balance standardization with product team ownership. With a separate infrastructure organization providing core services and some degree of standardization, organizations can reduce duplication of work compared to fully decentralized models. However, product teams retain autonomy over their application operations and provisioning requirements, allowing for a degree of flexibility. The tradeoff is that alignment between infrastructure and product groups is essential for smooth workflows, and there can still be duplication of work across product orgs.
Pros:
- Allows for strategic vision and strong opinions on infrastructure
- Achieves cost efficiencies through shared resources like shared clusters
- Removes operational burden of managing clusters from product orgs
- Eases visibility into usage and costs across product orgs
- Gives product orgs with predictability even if some constraints
- More easily adopts and enforces standards, best practices
Cons:
- Product orgs must use prescribed infra technologies which may not fit needs
- Bad central decisions have a large blast radius, negatively impacting all product orgs
- Difficult for product orgs to adopt new technologies on their own
- Does not eliminate difficulty of using provided infrastructure
- Forced migration to new technologies disrupts product orgs
Infrastructure-Platform Org and Product Orgs
The highly centralized Infrastructure-Platform Org model is ideal for larger organizations aiming for consistency across the organization and reducing duplication of work. By having a dedicated platform team owning all core infrastructure and standards, organizations can ensure uniformity and reduce cognitive load on product groups. However, the tradeoff is that the tight centralization can lead to the platform org drifting from actual product needs over time, and the accumulation of complex custom systems can hinder agility.
Pros:
- Lowers developer cognitive load by providing a unified SDK and abstraction layer
- Upgrading underlying infrastructure is cheaper overall as its done centrally
- Clear ownership for optimizing and simplifying the platform
- Limits infrastructure churn and “over-innovation” to one org
Cons:
- Forces developers to learn company-specific abstractions
- Once the company aligns on core tech, custom abstractions are seen as low value
- Brain drain or bad decisions have huge blast radius
- Perception of total cost of ownership of platform org is very high, creating continuous leadership friction
- Decomposing the Platform Org model into one of the previous ones requires changes on all product orgs and teams
Infrastructure Org + Intelligence-Assisted Model
For the majority of organizations that we’ve talked to, building and operating backend systems in the cloud remains unsustainably complex, driving up costs and reliance on scarce engineering expertise. Creating internal platform engineering teams seems promising initially, but these teams tend to accumulate custom implementations and abstraction layers that diverge from engineering needs over time. Platform teams get overloaded as workloads and technologies evolve over time, and the overhead of sustaining them outweighs the benefits as complexity is shifted rather than resolved.
The cloud is the platform
We believe that a better approach is to encapsulate this complexity behind accessible and intelligent tools designed for all application developers, while configured and operated by a central infrastructure org. Rather than funnel expertise into platform teams, it should be encoded into solutions that empower all developers. With abilities to reason about guardrails, optimizations, correctness, and evolving best practices baked in, these tools can encapsulate cloud complexity while enhancing productivity. This democratization of expertise through automation represents the future - one where any organization can reliably and sustainably build sophisticated backend systems in the cloud.
That’s where our InfraCopilot journey is headed. If you believe in this vision, let’s make that journey together!